
[AWS EBS (Elastic Block Store)]
- EBS볼륨은 한번에 하나의 인스턴스에만 붙일 수 있다.
- Q: 새로 생성되는 모든 볼륨이 항상 암호화된다고 확신할 수 있습니까?
예. 이제는 리전당 단일 설정을 사용하여 EBS 암호화를 기본적으로 활성화할 수 있습니다. 그리고 이렇게 하면 모든 새 볼륨이 항상 암호화됩니다
[AWS EFS]
EFS는 windows 인스턴스를 지원하지 않음.
FSx : Win, linux지원
EFS : Linux지원,
Lustre FSx : Linux지원,
SMB : FSx, storagegateway file gate지원
[AWS cloudFront]
웹 애플리케이션 방화벽 서비스인 AWS WAF를 사용하여 웹 액세스 제어 목록(웹 ACL)을 만들어 콘텐츠에 대한 액세스를 제한할 수 있습니다. 보안그룹 (Security Group)은 적용안됨(인스턴스에 적용 가능)
You can use CloudFront to deliver video on demand (VOD) or live streaming video using any HTTP origin. One way you can set up video workflows in the cloud is by using CloudFront together with AWS Media Services. https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/on-demand-streaming-video.html
원본 액세스 ID(OAI)를 사용하여 Amazon S3 콘텐츠에 대한 액세스 제한
Amazon S3 버킷에서 제공하는 콘텐츠에 대한 액세스를 제한하려면 다음 단계를 수행하세요.
1. 원본 액세스 ID(OAI)라는 특수 CloudFront 사용자를 만들어 배포와 연결합니다.
2. CloudFront에서 OAI를 사용하여 버킷의 파일을 액세스해 사용자에게 제공할 수 있도록 S3 버킷 권한을 구성합니다. 사용자가 S3 버킷에 대한 직접 URL을 사용하여 파일에 액세스할 수 없도록 해야 합니다.
이 단계를 수행하면 사용자가 S3 버킷에서 직접 액세스하지 않고 CloudFront를 통해서만 파일에 액세스할 수 있습니다.
FAQs
https://aws.amazon.com/ko/cloudfront/faqs/
- reographic restrictions 기능이 있어서 일부 국가에 대해서 엑세스 제한을 걸 수 있다.
- Users can used the cached function of CF to reduce the cost. => S3에서 데이터 요금이 많이 나올때 CloudFront의 캐쉬 기능으로 비용을 줄일 수 있다.
[ IOPS ]
~250 → 콜드 HDD (sc1)
~500 → 처리량 최적화 HDD(st1)
~16000 → 범용 SSD(gp2), gp3
~64000 → 프로비저닝된 IOPS SSD(io1), io2
[AWS Lamda]
15분 수행시간 제약 있음
[AWS WAF]
AWS WAF를 사용하여 차단할 수 있는 공격의 유형은 무엇입니까?
- SQL 명령어 주입과
- 교차 사이트 스크립팅(XSS) -> AWS Shield에는 없음
- 특정 사용자 에이전트, 특정 IP 주소로부터 트래픽을 차단
- 특정 요청 헤더를 포함하는 트래픽을 차단 또는 속도 제한
- 특정 국가만 허용하게 할 수 있다.
AWS의 GeoIP 데이터베이스는 얼마나 정확합니까? : 테스트에 따르면 국가/지역 매핑에 대한 IP 주소의 정확도는 99.8%입니다.
[Amazon Aurora Multi-Master를 통한 고가용성 MySQL 애플리케이션 만들기]
다중 마스터 클러스터의 모든 노드가 읽기/쓰기 노드이므로 Aurora 다중 마스터는 단일 쓰기 마스터를 가진 Aurora 보다 더 높은 가용성을 제공합니다. 아래 그림은 애플리케이션이 2개의 쓰기 노드를 선택적으로 사용할 수 있음을 보여줍니다. 단일 마스터 Aurora를 사용하면 단일 쓰기 노드가 실패하면 읽기 전용 복제본을 새 쓰기 마스터로 승격시켜야하고, 이 시간 동안 가용성이 확보되지 않습니다. 대신 Aurora 다중 마스터의 경우, 특정 쓰기 노드가 실패하면 다른 쓰기 노드에 대한 연결을 열면 됩니다.
[Amazon Route 53 라우팅 정책]
▶ 단순 라우팅 정책(Simple routing policy) - 도메인에 대해 특정 기능을 수행하는 하나의 리소스만 있는 경우(예: example.com 웹 사이트의 콘텐츠를 제공하는 하나의 웹 서버)에 사용합니다.
▶ 장애 조치 라우팅 정책(Failover routing policy) - 액티브-패시브 장애 조치를 구성하려는 경우에 사용합니다.
▶ 지리 위치 라우팅 정책(Geolocation routing policy) - 사용자의 위치에 기반하여 트래픽을 라우팅하려는 경우에 사용합니다.
▶ 지리 근접 라우팅 정책(Geoproximity routing policy) - 리소스의 위치를 기반으로 트래픽을 라우팅하고 필요에 따라 한 위치의 리소스에서 다른 위치의 리소스로 트래픽을 보내려는 경우에 사용합니다.
▶ 지연 시간 라우팅 정책(Latency routing policy) - 여러 AWS 리전에 리소스가 있고 왕복 시간이 적은 최상의 지연 시간을 제공하는 리전으로 트래픽을 라우팅하려는 경우에 사용합니다.
▶ 다중 응답 라우팅 정책(Multivalue answer routing policy) - Route 53이 DNS 쿼리에 무작위로 선택된 최대 8개의 정상 레코드로 응답하게 하려는 경우에 사용합니다.
▶ 가중치 기반 라우팅 정책(Weighted routing policy) - 사용자가 지정하는 비율에 따라 여러 리소스로 트래픽을 라우팅하려는 경우에 사용합니다.
[Amazon Routes alias, CNAME]
alias 레코드
별칭 레코드는 쿼리를 다음과 같이 선택한 AWS 리소스로만 리디렉션할 수 있습니다.
Amazon S3 버킷
CloudFront 배포
동일한 Route 53 호스팅 영역의 다른 레코드 예를 들어, acme.example.com이라는 이름의 Amazon S3 버킷으로 쿼리를 리디렉션하는 acme.example.com이라는 별칭 레코드를 생성할 수 있습니다. example.com 호스팅 영역의 zenith.example.com 레코드로 쿼리를 리디렉션하는 acme.example.com 별칭 레코드를 생성할 수도 있습니다.
CNAME 레코드
CNAME 레코드는 DNS 쿼리를 DNS 레코드로 리디렉션할 수 있습니다. 예를 들어 acme.example.com에서 zenith.example.com 또는 acme.example.org로 쿼리를 리디렉션하는 CNAME 레코드를 생성할 수 있습니다. 쿼리를 리디렉션할 도메인의 DNS 서비스로 Route 53을 사용할 필요가 없습니다.
[S3 Storage Class]
https://aws.amazon.com/ko/s3/storage-classes/
Amazon S3 Glacier Deep Archive : - 가장 저렴한 비용의 스토리지 클래스이며 1년에 한두 번 정도 액세스할 수 있는 데이터에 적합. - 7~10년 이상 데이터를 보관하는 고객을 위해 설계되었습니다. - 자기 테이프 시스템에 대한 비용 효과적이고 관리하기 쉬운 대안입니다. - S3 Glacier Deep Archive는 Amazon S3 Glacier를 보완하며, 12시간 이내에 복원할 수 있습니다.
S3 Glacier Instant Retrieval (65% lower than S3 Standard-IA) :
miliseconds retrieval
S3 Glacier Flexible Retrieval (10% lower than Glacier Instant Retrieval) :
expediated : 1~5 mins 이내
standard옵션 : 3~5 hours 이내
bulk옵션 : 5~12 hours 이내
S3 Glacier Deep Archive (75% lower than Glacier) :
standard옵션 : 12 hours 이내
bulk옵션 : 48 hours 이내
[S3 Glacier Archive 가져오기]
● 신속 —신속 검색을 사용하면 일부 아카이브의 하위 집합을 긴급하게 요청해야 하는 경우 S3 Glacier Flexible Retrieval 스토리지 클래스 또는 S3 Intelligent-Tiering Archive Access 계층에 저장된 데이터에 신속하게 액세스할 수 있습니다. 매우 큰 아카이브(250MB+)를 제외한 모든 경우, 신속 가져오기를 사용하여 액세스된 데이터는 일반적으로 1~5분 안에 사용할 수 있게 됩니다. 프로비저닝된 용량을 통해 필요할 때 신속 검색에 대한 검색 용량이 보장됩니다. 자세한 정보는 프로비저닝된 용량을 참조하십시오.
● 표준 —표준 가져오기를 사용하면 몇 시간 내에 아카이브에 액세스할 수 있습니다. 표준 검색은 보통 3~5시간 안에 완료됩니다. 검색 요청 시 검색 옵션을 지정하지 않을 경우 기본 옵션이 됩니다.
● 대량 —대량 가져오기는 S3 Glacier에서 가장 저렴한 가져오기 옵션으로, 즉 페타바이트 규모의 대용량 데이터를 하루 동안 가져올 때 사용할 수 있습니다. 벌크 검색은 보통 5~12시간 안에 완료됩니다.
Amazon S3 Glacier는 최소스토리지 기간을 90일 지속해야 함. (90일전에 삭제시 과금 발생)
"현재 Snowball Edge를 사용하여 S3 Glacier에 직접 객체를 업로드할 수 있는 방법은 없습니다. 따라서 먼저 객체를 S3 Standard에 업로드한 다음 S3 수명 주기 정책을 사용하여 파일을 S3 Glacier로 전환해야 합니다." 라고 aws document에 있네요.
[AWS Fargate]
기본적으로 Fargate 태스크는 가용 영역에 분산되어 있습니다.
[AWS Global Accelerator]
Q: How is AWS Global Accelerator different from Amazon CloudFront?
A: AWS Global Accelerator and Amazon CloudFront are separate services that use the AWS global network and its edge locations around the world. CloudFront improves performance for both cacheable content (such as images and videos) and dynamic content (such as API acceleration and dynamic site delivery). Global Accelerator improves performance for a wide range of applications over TCP or UDP by proxying packets at the edge to applications running in one or more AWS Regions. Global Accelerator is a good fit for non-HTTP use cases, such as gaming (UDP), IoT (MQTT), or Voice over IP, as well as for HTTP use cases that specifically require static IP addresses or deterministic, fast regional failover. Both services integrate with AWS Shield for DDoS protection.
AWS Global Accelerator : 글로벌 사용자에게 제공하는 네트워킹 서비스입니다. 고정 IP 주소를 통해 고정된 진입점을 제공하고, 서로 다른 AWS 리전 및 가용 영역별로 특정 IP 주소를 관리하는 복잡성을 없앱니다. AWS Global Accelerator는 애플리케이션 상태, 사용자의 위치 및 고객이 구성하는 정책의 변경에 즉각적으로 대응하여 항상 성능에 기반한 최적의 엔드포인트로 사용자 트래픽을 라우팅합니다.
[AWS Global Accelerator 표준 가속기에 대한 엔드포인트 그룹]
엔드포인트 그룹은 AWS Global Accelerator 에 등록된 엔드포인트로 요청을 라우팅합니다. 표준 가속기에 수신기를 추가할 때 글로벌 가속기에서 트래픽을 전달하기 위한 끝점 그룹을 지정합니다. 엔드포인트 그룹과 이 그룹의 모든 엔드포인트는 하나의 AWS 리전에 속해야 합니다. 파란색/녹색 배포 테스트와 같이 다른 목적을 위해 서로 다른 끝점 그룹을 추가할 수 있습니다.
[Amazon S3 Transfer Acceleration]
Amazon S3 Transfer Acceleration은 더 큰 객체의 장거리 전송을 위해 Amazon S3와 주고받는 콘텐츠 전송 속도를 최대 50-500%까지 높일 수 있습니다. 광범위한 사용자가 있는 웹 또는 모바일 애플리케이션이 있거나 S3 버킷에서 멀리 떨어진 애플리케이션을 호스팅하는 고객은 인터넷을 통해 길고 다양한 업로드 및 다운로드 속도를 경험할 수 있습니다.
비디오 파일의 업/다운로드의 경우 Amazon S3 Transfer Acceleration 의 특징인 "더 빠른 장거리 S3 업로드 및 다운로드 기능"을 사용해야 한다.
[AWS Redshift]
Enable cross-Region snapshots. (교차리전 스냅샷. 재해 복구 위해)
Multi-AZ is not supported with RedShift. (Multi-AZ는 지원하지 않음)
[no communication occurs over the internet between the instances.]
① AWS VPC와 On-premise의 연결 → VPN or DX (Direct Connect)
② AWS VPC와 AWS VPC의 1:1 연결 → VPC Peering
③ 다수의 AWS VPC 들과 On-premise 간의 연결 → TGW (Transit Gateway)
④ AWS VPC 내부 인스턴스와 AWS VPC 외부 서비스의 연결 → Internet Gateway, NAT Gateway (인터넷 경유 필요) / VPC Endpoint Interface, VPC Endpoint Gateway (인터넷 경유 필요 없음, 예: VPC내 EC2와 외부 S3간의 안전한 연결)
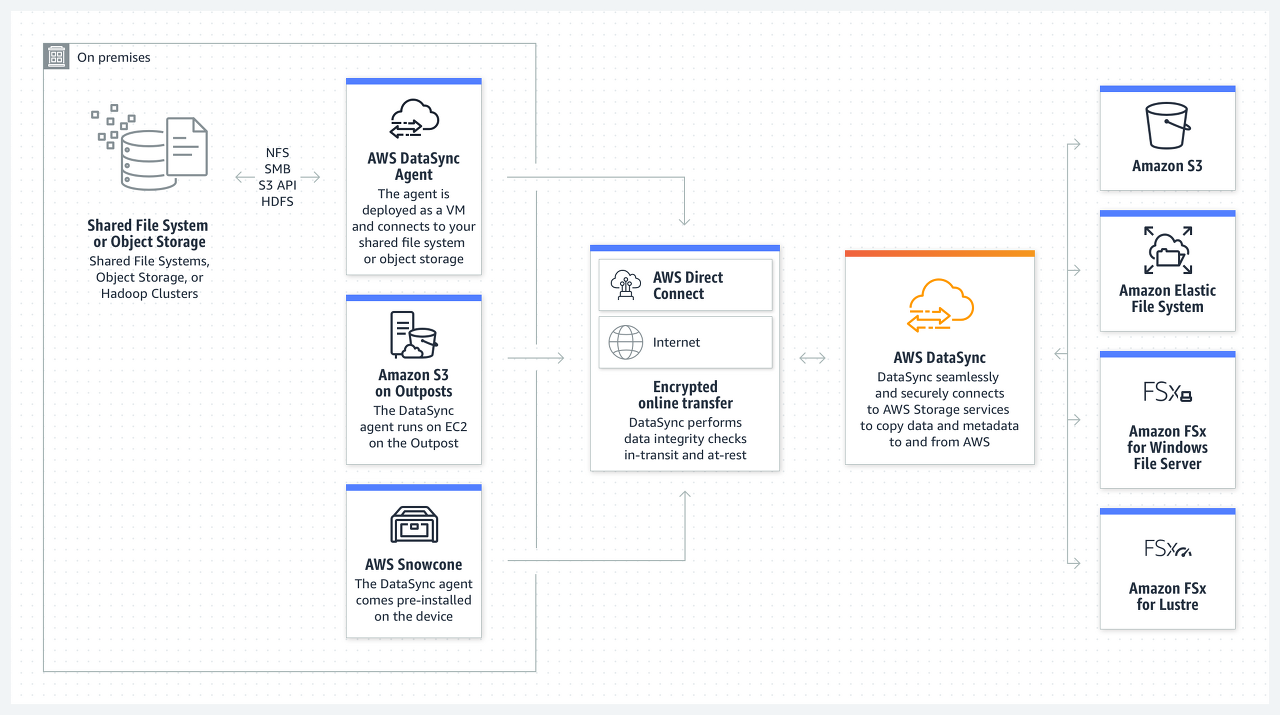
[Q: 언제 AWS DataSync를 사용하고 언제 AWS Storage Gateway를 사용해야 합니까?]
AWS DataSync -> AWS Storage Gateway
A: AWS DataSync를 사용하여 기존 데이터를 Amazon S3로 마이그레이션한 다음, 이후 AWS Storage Gateway의 파일 게이트웨이 구성을 사용하여 마이그레이션된 데이터 및 온프레미스 파일 기반 애플리케이션의 지속적인 업데이트에 대한 액세스를 유지합니다. DataSync와 파일 게이트웨이를 함께 사용하면 온프레미스 애플리케이션을 클라우드 스토리지에 원활하게 연결하면서 온프레미스 인프라를 최소화할 수 있습니다. AWS DataSync는 AWS 스토리지 서비스로의 온라인 데이터 전송을 자동화하고 가속합니다. AWS DataSync를 사용하는 초기 데이터 전송 단계 이후에 파일 게이트웨이는 온프레미스 애플리케이션에서 마이그레이션된 데이터에 대한 액세스의 지연 시간을 줄여줍니다. NFS 공유에서 DataSync를 사용하는 경우 소스 온프레미스 스토리지의 POSIX 메타데이터가 보존되며, 파일 게이트웨이를 사용하여 파일에 액세스할 때 소스 스토리지의 권한이 적용됩니다.
AWS Storage Gateway
AWS Storage Gateway는 거의 무제한의 클라우드 스토리지 액세스를 온프레미스에 제공하는 하이브리드 클라우드 스토리지 서비스 세트입니다.

AWS DataSync
[VPC Gateway Endpoint, VPC Interface(privateLink)]
A) CORRECT -> Gateway VPC endpoints are only available for S3 and DynamoDB
B) VPC interfaces or by other name AWS privateLink is only available for s3 (https://docs.aws.amazon.com/vpc/latest/privatelink/integrated-services-vpce-list.html)
C) Interface VPC is not available for Dynamo, only for S3
D) It is possible, but I don't think it's correct for this requirement
VPC End Point 에 대한 이해
* Gateway End Point : VPC용 Internet Gateway 또는 NAT 디바이스없이 S3 및 Danamo DB에 대한 안정적인 연결을 제공. AWS Private Link를 활성화 하지 않는다.
* Interface End Point VPC에서 Route Table에 지정하는 Gateway. Private IP주소를 통하여 On premise VPC, VPC Peering 또는 Aws Transit Gateway로 다른 region의 VPC에서 Access가 가능하다.
게이트웨이 엔드포인트는 AWS 네트워크를 통해 VPC에서 Amazon S3에 액세스하기 위해 라우팅 테이블에 지정하는 게이트웨이입니다.
인터페이스 엔드포인트는 프라이빗 IP 주소를 통해 온프레미스의 VPC 내에서 또는 VPC 피어링이나 AWS Transit Gateway를 사용하여 다른 AWS 리전의 VPC에서 Amazon S3로 요청을 라우팅함으로써 게이트웨이 엔드포인트의 기능을 확장합니다. 자세한 내용은 VPC 피어링이란 및 Transit Gateway 및 VPC 피어링을 참조하세요.
인터페이스 엔드포인트는 게이트웨이 엔드포인트와 호환됩니다. VPC에 기존 게이트웨이 엔드포인트가 있는 경우, 동일한 VPC에서 두 가지 유형의 엔드포인트를 모두 사용할 수 있습니다.
| 두 경우 모두, 네트워크 트래픽은 AWS 네트워크에 남아 있습니다. | |
| Amazon S3 퍼블릭 IP 주소 사용 | VPC의 프라이빗 IP 주소를 사용하여 Amazon S3에 액세스 |
| 온프레미스에서의 액세스 허용하지 않음 | 온프레미스에서의 액세스 허용 |
| 다른 AWS 리전에서의 액세스를 허용하지 않음 | VPC 피어링 또는 AWS Transit Gateway를 사용하여 다른 AWS 리전의 VPC에서 액세스 허용 |
| 미청구 | 청구 |
[마이그레이션 전략 7R]
▶Rehost: 리호스팅 (리프트 앤 시프트) - 온프레미스 아키텍처를 클라우드에 복제 - 마이그레이션된 리소스는 최소한의 변경만 필요할 수 있음
▶Relocate: 재배치 - 클라우드에서 동일한 기본 기술을 사용할 수 있는 애플리케이션 이동 ex) 컨테이너화된 애플리케이션 마이그레이션, Vmware이미지를 VMware Cloud on AWS로 이동, ...
▶Replatform: 리플랫포밍 (리프트 앤 리셰이프) - 클라우드 마이그레이션의 일환으로 플랫폼 변경 ex) OS 또는 DB 엔진 변경, 최신 애플리케이션 릴리스로 업그레이드, RISC에서 x86으로 변경, ...
▶Repurchase: 재구매 (드롭 앤 숍) - 새 애플리케이션으로 교체 ex) 애플리케이션을 SaaS 제품 또는 COTS 제품으로 교체, 클라우드 호환 가능 라이선스 구매 ...
▶Refactor: 리팩터링 - 애플리케이션 바이너리를 클라우드로 마이그레이션하기 전에 변경 - 애플리케이션의 대대적 리팩터링 또는 소규모 리팩터링이 될 수 있음 ex) 데이터베이스 전환, 미들웨어 변경, 애플리케이션 구성 요소 재코딩, 애플리케이션 아키텍처 재구축, ...
▶Retain: 유지 - 서버 또는 애플리케이션을 이동하지 않고 소스(온프레미스) 환경에서 계속 운영
▶Retire: 사용중지 - 소스(온프레미스) 환경에서 서버 또는 애플리케이션 폐기
[AWS EC2]
Placement groups 3가지
1. Cluster placement groups 클러스터 배치 그룹은 단일 가용 영역 내에 있는 인스턴스의 논리적 그룹입니다. 클러스터 배치 그룹은 동일한 리전의 피어링된 VPC에 걸쳐 적용될 수 있습니다. 동일한 클러스터 배치 그룹의 인스턴스는 TCP/IP 트래픽에 더 높은 흐름당 처리량 제한을 제공하며 네트워크의 동일한 높은 양방향 대역폭 세그먼트에 배치됩니다.
2. Partition placement groups 파티션 배치 그룹은 애플리케이션에 대한 상관 관계가 있는 하드웨어 장애 가능성을 줄이는 데 도움이 됩니다. 파티션 배치 그룹을 사용하는 경우 Amazon EC2는 각 그룹을 파티션이라고 하는 논리 세그먼트로 나눕니다. Amazon EC2는 배치 그룹 내 각 파티션에 자체 랙 세트가 있는지 확인합니다. 각 랙은 자체 네트워크 및 전원이 있습니다. 배치 그룹 내 두 파티션이 동일한 랙을 공유하지 않으므로 애플리케이션 내 하드웨어 장애의 영향을 격리시킬 수 있습니다.
3. Spread placement groups 분산형 배치 그룹은 각각 고유한 랙에 배치된 인스턴스 그룹이며 랙마다 자체 네트워크 및 전원이 있습니다. 분산형 배치 그룹에서 인스턴스를 시작하면 인스턴스가 동일한 랙을 공유할 때 장애가 동시에 발생할 수 있는 위험이 줄어듭니다. 분산형 배치 그룹은 별개의 랙에 대한 액세스를 제공하기 때문에 시간에 따라 인스턴스를 시작하거나 인스턴스 유형을 혼합할 때 적합합니다.
1) cluster: AZ 안에 instance들을 근접하게 패킹한다. - 짧은 네트워크 지연 시간 - 높은 네트워크 처리량
2) partition: instance를 논리적 파티션에 분산하여 한 파티션에 있는 인스턴스 그룹이 다른 파티션 인스턴스 그룹과 HW를 공유할 수 없다. -> 하둡, Cassandra, Kafka 등에 필요
3) 분산: 소규모 인스턴스그룹을 다른 HW로 분산하여 상호관련 오류를 낮춘다.
- 일단 클러스터 배치그룹은 멀티 AZ를 지원하지 않는다네요.
EC2 Auto scaling group
An Auto Scaling group can contain Amazon EC2 instances from multiple Availability Zones within the same Region. However, an Auto Scaling group can't contain instances from multiple Regions.
[DDoS 공격을 감지하고 방어하기 위한 솔루션]
A) Amazon GuardDuty : AWS 계정 및 워크로드에서 악의적 활동을 모니터링하고 상세한 보안 결과를 제공하여 가시성 및 해결을 촉진하는 위협 탐지 서비스. 공격 감지는 되나 방어가 되지 않음
B) Amazon Inspector : SW 취약성 및 의도하지 않은 네트워크 노출에 대해 AWS 워크로드를 지속적으로 스캔하는 자동화된 취약성 관리 서비스 => 방어X
C,D) AWS Shied : AWS에서 실행되는 application을 보호하는 DDoS 보호 서비스. AWS Shield Standard, Advanced 두 종류가 있음.
Standard : Amazon CouldFront Amazon Route 53과 함께 사용하면, 계층 3 및 4의 모든 인프라 공격으로부터 가용성을 포괄적으로 보호할 수 있다. (모든 계층에 대한 보호는 아니므로 D가 더 적합)
Advanced : EC2, ELB, CloudFront, Global Accelerator 및 Route 53 리소스에서 실행되는 application 을 표로 하는 공격에 대해 더 높은 수준의 보호를 구현. 정교한 대규모 DDoS 공격에 대한 추가 보호 및 완화, 실시간에 가까운 공격에 대한 가시성, AWS WAF와의 통합을 제공한다.
[Backup 용량 계산]
예) 500MBps, 700TB를 30일에 전송 가능한가?
초당 전송가능 용량 500 / 8 = 62.5 MB
30일 = 30 * 24 * 60 * 60 = 2592000 초
30일 전송가능 용량 = 62.5MB * 2592000 = 162187500MB = 154.67TB
네트워크로는 1개월 내에 700TB 전송 불가
[Service Control Poliocy]
조직의 권한을 관리하는 데 사용할 수 있는 조직 정책 유형입니다. SCP는 조직의 모든 계정에 사용 가능한 최대 권한을 중앙에서 제어합니다. SCP를 사용하면 조직의 액세스 제어 지침에 따라 계정을 유지할 수 있습니다. SCP는 활성화된 모든 기능을 가진 조직에서만 사용할 수 있습니다.
[IAM - Use a cross-account role with an external ID]
AWS 리소스에 대한 액세스 권한을 서드 파티에 부여할 때 외부 ID를 사용 이따금 AWS 리소스에 대한 액세스를 타사에 부여해야 할 때가 있습니다(액세스 위임). 이 시나리오의 한 가지 중요한 부분은 IAM 역할 신뢰 정책에서 역할 수임자를 지정하는 데 사용할 수 있는 옵션 정보인 external ID 입니다.
AWS Shield : 디도스(DDoS) 보호 서비스
AWS WAF : 방화벽
Amazon Inspector : 애플리케이션 보안 분석 ->소프트웨어 취약성 및 의도하지 않은 네트워크 노출에 대해 AWS 워크로드를 지속적으로 스캔하는 자동화된 취약성 관리 서비스입니다.
Amazon GuardDuty : 관리형 위험 탐지 서비스 -> AWS 계정 및 워크로드에서 악의적 활동을 모니터링하고 상세한 보안 결과를 제공하여 가시성 및 해결을 촉진하는 위협 탐지 서비스
[AWS OpenSearch service]
https://aws.amazon.com/ko/opensearch-service
Amazon OpenSearch Service는 대화형 로그 분석, 실시간 애플리케이션 모니터링 및 웹사이트 검색 등을 쉽게 수행할 수 있게 해줍니다. OpenSearch는 Elasticsearch에서 파생된 오픈 소스, 분산 검색 및 분석 제품군입니다. Amazon OpenSearch Service는 Amazon Elasticsearch Service의 후속으로 최신 버전의 OpenSearch을 제공하며, 19가지 버전의 Elasticsearch(버전 1.5~7.10)를 지원하고 OpenSearch Dashboards와 Kibana(버전 1.5~7.10)이 제공하는 시각화 기능을 제공합니다.
[AWS QuickSight]
비즈니스 분석 서비스로서, 데이터를 사용해 손쉽게 시각화를 구축. CSV 파일과 Excel 파일을 업로드하고, Salesforce와 같은 SaaS 애플리케이션에 연결하고, SQL Server, MySQL 및 PostgreSQL과 같은 온프레미스 데이터베이스에 액세스하고, Amazon Redshift, Amazon RDS, Amazon Aurora, Amazon Athena 및 Amazon S3와 같은 AWS 데이터 소스를 원활하게 검색할 수 있습니다.
[AWS Redshift Spectrum]
Amazon Redshift Spectrum을 사용하면 데이터를 Amazon Redshift 테이블에 로드하지 않고도 Amazon S3의 파일에서 정형 및 비정형 데이터를 효율적으로 쿼리하고 가져올 수 있습니다. Redshift Spectrum 쿼리는 대량 병렬 처리를 채택해 큰 데이터 집합에 대해 매우 빠르게 실행됩니다. 대부분의 처리가 Redshift Spectrum 계층에서 이루어지며, 데이터가 대부분 Amazon S3에 그대로 남습니다. 또한 다수의 클러스터가 Amazon S3의 동일한 데이터 집합에 대해 동시에 쿼리를 실행할 수 있기 때문에 각 클러스터의 데이터를 일일이 복사할 필요가 없습니다
[AWS Database]
Aurora MySQL(MariaDB) - Cross-Region Multi-AZ 지원
Microsoft SQL Server, PostgresSQL, Oracle DB instances는 "Cross-Region Multi-AZ isn't supported."
Aurora 백업 보존 기간은 DB 클러스터를 생성 또는 설정 변경할 때 1일에서 35일까지 지정할 수 있습니다. Aurora 백업은 Amazon S3에 저장됩니다. -> 90일 백업은 AWS Backup 을 활용해서 수동 백업
[AWS Inspector]
Amazon Inspector는 소프트웨어 취약성 및 의도하지 않은 네트워크 노출에 대해 AWS 워크로드를 지속적으로 스캔하는 자동화된 취약성 관리 서비스입니다.
- 신속하게 취약성 발견
- 패치 수정 우선순위 지정 (소프트웨어 패치, EC2) -규정 준수 요구 사항 충족
- 더 빠르게 제로 데이 취약성 식별 -Amazon EC2 및 ECR 모두에 대한 취약성 관리 솔루션을 하나의 완전관리형 서비스
- 클릭 한 번으로 AWS 워크로드에서 소프트웨어 취약성과 의도하지 않은 네트워크 노출을 즉시 발견
[AWS GuardDuty]
Amazon GuardDuty는 AWS 계정 및 워크로드에서 악의적 활동을 모니터링하고 상세한 보안 결과를 제공하여 가시성 및 해결을 촉진하는 위협 탐지 서비스입니다.
- 무단 활동 차단
- 지속적인 모니터링 및 분석 지원
- 포렌식 간소화
- Amazon Simple Storage Service(S3) 내 비정상적인 데이터 액세스, 악의적인 것으로 알려진 IP 주소에서의 API 호출 등으로부터 계정 및 데이터를 보호합니다.
[AWS Direct Connect(DX])]
Direct Connect Location이란?
AWS에서는 각 리전 마다 한 개 이상의 AWS Direct Connect Location(이하, DX Location)을 지정하여 각 AZ에 있는 자원들을 빠른 네트워크 환경에서 연결할 수 있습니다.
DX Location은 망 중립성을 제공하는 로컬 데이터 센터 사업자 중 AWS에서 지정하는 데이터 센터 상면 공급 사업자입니다.
해당 사업자의 상면에 AWS에서 네트워크 장비들을 설치하고, 백엔드로 AWS 모든 가용 영역(AZ)과 고속 전용 회선을 통해 연결해 놓은 곳을 의미합니다.
좀 더 쉽게 말씀 드리면, AWS 리전 내 만들어진 모든 클라우드 자원과 단일 회선 연동을 통해 연결될수 있도록 해 주는 브로커 역할을 수행합니다. 전 세계에 리전별로 다수의 AWS DX Location이 운영되고 있습니다.
AWS Direct Connect 서비스를 구성하기 위해서는 몇 가지 단계를 거쳐야 합니다. 첫 번째 단계는 전용 회선을 여러분의 데이터 센터에서 DX Location까지 연결 하는 것이고, 그 다음에는 AWS 관리 콘솔에서 연결 설정을 수행하는 것입니다. https://aws.amazon.com/ko/blogs/korea/how-to-aws-direct-connect-to-seoul-region/
VPN 연결과 달리 Direct Connect 링크는 암호화 기능을 제공하지 않지만 AWS 엔드포인트가 이미 TLS로 암호화돼 있으므로 온프레미스 네트워크와 AWS 간의 연결은 안전한 상태를 유지할 수 있다.
[AWS Cost Explorer]
시간에 따른 AWS 비용과 사용량을 시각화, 이해 및 관리할 수 있는 손쉬운 인터페이스를 제공합니다. 비용 및 사용량 데이터를 분석하는 사용자 지정 보고서를 작성하여 신속하게 시작합니다. 데이터를 높은 수준으로 분석 (예: 모든 계정의 총 비용 및 사용량)하거나 비용 및 사용량 데이터를 자세히 분석하여 추세를 식별하고 비용 동인을 파악하고 이상을 탐지합니다 최대 지난 12개월간의 데이터를 보고, 이후 12개월 동안 지출할 것으로 예상되는 금액을 예측하며, 구매할 예약 인스턴스에 대한 추천을 받을 수 있습니다.
[AWS Budgets (예산 예측~~~)]
유동적인 예산 및 예측 기능을 사용해 계획 및 비용 제어 과정 개선 기업과 조직은 클라우드 비용을 계획하고 예상해야 합니다. 하지만 클라우드 환경은 빠르게 바뀌고 있으므로 사용량의 변화에 따라 예측 프로세스와 도구도 적절하게 조정해야 합니다. AWS 예산 사용 시에는 사용자 지정 예산을 설정할 수 있으며, 시간별 비용/사용량을 지속적으로 파악하여 비용이나 사용량이 임계값을 초과하면 신속하게 대응할 수 있습니다. AWS 예산에서는 사용자 지정 예산을 설정하여 난이도가 각기 다른 여러 사용 사례의 비용과 사용량을 추적할 수 있습니다
[AWS Multi-AZ]
Multi-AZ RPO is zero: https://aws.amazon.com/blogs/database/managed-disaster-recovery-with-amazon-rds-for-sql-server-using-cross-region-automated-backups/#:~:text=Amazon%20RDS%20Multi,0
[AWS Macie]
Amazon Macie는 완전관리형 데이터 보안 및 데이터 프라이버시 서비스로서, 기계 학습 및 패턴 일치를 활용하여 AWS에서 민감한 데이터를 검색하고 보호합니다.
기업에서 관리하는 데이터 볼륨이 증가함에 따라 대규모로 민감한 데이터를 식별하고 보호하는 작업이 점점 더 복잡해지고 비용과 시간이 많이 소요될 수 있습니다. Amazon Macie를 사용하면 민감한 데이터를 대규모로 자동 검색하고 데이터 보호 비용을 절감할 수 있습니다. Macie는 암호화되지 않은 버킷, 공개적으로 액세스 가능한 버킷, AWS Organizations에 정의되지 않은 AWS 계정과 공유된 버킷의 목록을 비롯하여 Amazon S3 버킷의 인벤토리를 자동으로 제공합니다. 그런 다음 Macie는 선택한 버킷에 기계 학습 및 패턴 매칭 기법을 적용하여 개인 식별 정보(PII)와 같은 민감한 데이터를 식별하고 사용자에게 알립니다.
[AWS Billing Dashboard]
https://docs.aws.amazon.com/ko_kr/awsaccountbilling/latest/aboutv2/view-billing-dashboard.html
[AWS Cost Explorer]
https://aws.amazon.com/ko/aws-cost-management/aws-cost-explorer/
[AWS ECS]
Rolling update
https://docs.aws.amazon.com/ko_kr/AmazonECS/latest/developerguide/deployment-type-ecs.html
[AWS Key Management System(KMS)]
AWS 관리형 키 - AWS 관리형 키는 AWS KMS와 통합된 AWS 서비스가 고객의 계정에서 고객 대신 생성, 관리 및 사용하는 KMS 키입니다. 모든 AWS 관리형 키는 3년마다 자동으로 교체됩니다. 이 교체 일정은 변경할 수 없습니다.
AWS KMS 고객 관리형 키 -
사용자가 생성하는 KMS 키는 고객 관리형 키입니다. 고객 관리형 키는 사용자가 생성, 소유 및 관리하는 AWS 계정의 KMS 키입니다. 고객 관리형 KMS 키에 대한 자동 키 교체는 기본적으로 비활성화됩니다. 자동 키 교체를 활성화(또는 다시 활성화)하면 AWS KMS는 활성화 날짜에서 365일 후에 KMS 키를 자동으로 교체하고 이후 365일마다 교체합니다.
AWS KMS key 교체
https://docs.aws.amazon.com/ko_kr/kms/latest/developerguide/rotate-keys.html
[AWS NACL]
낮은 번호로 Deny 규칙 추가 -> 낮은 번호의 rule이 먼저 수행됨.
[AWS SQS]
SQS 접근 권한을 부여하는 방법은 크게 두가지가 있습니다.
IAM Policy를 만들어 User, User group, Role에 부여하는 자격증명 기반 정책(Identity Based)과 AWS 리소스 자체에 접근 권한 정책을 정의하는 리소스 기반 정책(Resource Based)입니다.
리소스 기반 정책은 자격증명 기반 정책과 다르게 접근 가능한 대상을 Principal 항목에 명시함으로써 접근 대상을 관리할 수 있으며 S3, SQS, Glacier, KMS 등의 리소스에 적용할 수 있습니다.
"The other corporation want to poll the queue without granting access to its own account." 문제의 위와 같은 조건에 따라 자격증명 기반 정책이 아닌 리소스 기반 정책을 사용하는 것이 정답인 것 같습니다.
[AWS DynamoDB]
- Amazon DynamoDB with on-demand enabled (필요에 의해 확장하고 수정함)
- Amazon DynamoDB with DynamoDB Streams enabled (변경 사항을 스트림으로 캡쳐함)
[AWS Virtual Private Gateway vs Direct Connet Gateway vs Transit Gateway]
- Virtual Private Gateway : VPN 연결을 생성할때 사용되는 VPC 리소스. VPC는 하나의 연결이 다른 요소와의 연결로 확장되는 전이 라우팅(transitive routing)을 지원하지 않는다.
https://www.megaport.com/blog/aws-vgw-vs-dgw-vs-tgw/
[AWS Spot Fleet]
Spot Fleet = 스팟인스턴스 + 온디맨드 (예약가능) 스팟 플릿은 사용자가 지정한 기준에 따라 시작되는 스팟 인스턴스의 집합이며 선택적으로 온디맨드 인스턴스 집합입니다. 스팟 플릿은 사용자의 요구 사항을 충족하는 스팟 용량 풀을 선택하고 플릿에 대한 목표 용량을 충족하는 스팟 인스턴스를 시작합니다. 기본적으로 스팟 집합은 플릿에서 스팟 인스턴스가 종료된 후 교체 인스턴스를 시작하여 목표 용량을 유지하도록 설정되어 있습니다. 스팟 플릿을 인스턴스가 종료된 후에는 유지되지 않는 일회성 요청으로 제출할 수도 있습니다. 스팟 플릿 요청에 온디맨드 인스턴스 요청을 포함할 수 있습니다.
[외부 전용 인터넷 게이트웨이]
요구조건 : (IPv6 EC2상에서 호스팅되는)앱이 인터넷을 통해 외부 응용과 통신해야 함
"IPv6 주소는 전역적으로 고유하므로 퍼블릭으로 기본 설정되어 있습니다. 인스턴스가 인터넷에 액세스할 수 있게 하되 인터넷 상의 리소스가 해당 인스턴스와의 통신을 시작하지 못하게 하려면 외부 전용 인터넷 게이트웨이를 사용하면 됩니다. 이렇게 하려면 VPC에 외부 전용 인터넷 게이트웨이를 만들어 라우팅 테이블에 모든 IPv6 트래픽(::/0)을 가리키는 라우팅을 추가하거나 IPv6 주소의 특정 범위를 외부 전용 인터넷 게이트웨이에 추가합니다. 라우팅 테이블에 연결된 서브넷의 IPv6 트래픽은 외부 전용 인터넷 게이트웨이로 라우팅됩니다. 외부 전용 인터넷 게이트웨이는 상태 저장 방식으로서, 서브넷의 인스턴스에서 인터넷 또는 기타 AWS 서비스로 트래픽을 전달한 다음, 다시 인스턴스로 응답을 보냅니다."
[RPO(복구 시점 목표)와 RTO(복구 시간 목표)]
이러한 용어는 재해 발생 시 워크로드 가용성을 복구하기 위한 목표 및 전략 세트인 DR(재해 복구)과 가장 자주 관련됩니다.
RTO(복구 시간 목표) 조직에서 정의합니다. RTO는 서비스 중단 시점과 서비스 복원 시점 간에 허용되는 최대 지연 시간으로, 서비스를 사용할 수 없는 상태로 허용되는 기간을 결정합니다.
RPO(복구 시점 목표) 조직에서 정의합니다. RPO는 마지막 데이터 복구 시점 이후 허용되는 최대 시간으로, 마지막 복구 시점과 서비스 중단 시점 사이에 허용되는 데이터 손실량을 결정합니다.

RPO(복구 시점 목표), RTO(복구 시간 목표) 및 재해 이벤트의 관계.
RTO는 중단이 시작된 시점과 워크로드 복구 사이의 시간을 측정한다는 점에서 MTTR(평균 복구 시간)과 유사합니다. 하지만 MTTR은 일정 기간에 여러 가용성에 영향을 미치는 이벤트에 대한 평균 값이며, RTO는 단일 가용성에 영향을 미치는 이벤트의 목표 값 또는 최대 허용 값입니다.
[Amazon EMR]
Amazon Web Services에서 제공하는 서비스와 Apache Hadoop을 사용하여 손쉽게 방대한 양의 데이터를 효율적으로 처리할 수 있는 웹 서비스입니다. 기계 학습, 과학 시뮬레이션, 데이터 마이닝, 웹 인덱싱, 로그 파일 분석 및 데이터 웨어하우징용 데이터를 처리하고 분석합니다.
[S3 객체 소유권]
객체 소유권에는 버킷에 업로드된 객체의 소유권을 제어하고 ACL을 사용 중지하거나 사용하는 다음과 같은 세 가지 설정이 있습니다.
ACL 사용 중지됨 버킷 소유자 시행(Bucket owner enforced)(권장) – ACL이 사용 중지되고 버킷 소유자는 버킷의 모든 객체를 자동으로 소유하고 완전히 제어합니다. ACL은 더 이상 S3 버킷의 데이터에 대한 권한에 영향을 주지 않습니다. 버킷은 정책을 사용하여 액세스 제어를 정의합니다.
ACL 사용됨 버킷 소유자 기본(Bucket owner preferred) – 버킷 소유자가 bucket-owner-full-control 미리 제공 ACL을 사용하여 다른 계정이 버킷에 작성하는 새 객체를 소유하고 완전히 제어합니다.
객체 작성자(Object writer)(기본값) – 객체를 업로드하는 AWS 계정은 객체를 소유하고 완전히 제어하며 ACL을 통해 다른 사용자에게 이에 대한 액세스 권한을 부여할 수 있습니다.

